Joint Space Control#
Overview of Robot Control#
The control of a robot arm is to determine the time sequence of control inputs (i.e., joint torques) to achieve a specified task. A task is specified usually in the operational space (such as end-effector motion and forces), whereas control inputs (joint torque) is usually made in the joint space. There are two control schemes: joint space control and operational space control.

Fig. 65 Joint space control#
The joint space control is shown in Fig. 65. Here, inverse kinematics is use to convert the specified end-effector motion \(\boldsymbol{x}_{d}\) to the desired joint motion \(\boldsymbol{q}_{d}\). Then, a joint space controller is designed to allow the actual joint value \(\boldsymbol{q}\) to track \(\boldsymbol{q}_{d}\). The controller directly regulates the joint tracking error \(\boldsymbol{q}_{d}-\boldsymbol{q}_{}\), instead of operational space error \(\boldsymbol{x}_{d}-\boldsymbol{x}_{e}\). Thus, the end-effector pose \(\boldsymbol{x}_{e}\) is controlled in an open-loop fashion.

Fig. 66 Operational space control#
The operational space control is shown in Fig. 66. Here, the operational space motion \(\boldsymbol{x}_{e}\) is directly fed back to the controller. Thus, it addresses the drawbacks of joint space control. However, the control typically is more complex in design and requires measuring the operational space motion \(\boldsymbol{x}_{e}\).
Joint Space Control#
For a \(n\)-joint robot arm, we consider a robot arm without external end-effector forces and joint friction. The equation of motion of the robot arm is
The controller we want to design is
i.e., the controller takes the robot current joint position \(\boldsymbol{q}\), joint velocity \(\boldsymbol{\dot{q}}\), desired joint position \(\boldsymbol{q}_d\), and desired joint velocity \(\boldsymbol{\dot{q}}_d\), and outputs joint torque \(\boldsymbol{u}\).
The motion of equation of the robot arm with the controller is (also called closed-loop dynamics):
Controller 1: PD Control with Gravity Compensation#
Consider a stationary desired joint position \(\boldsymbol{q}_{d}\) (\(\boldsymbol{\dot q}_{d}=\boldsymbol{0}\)), we want to design a controller (52), such that given any initial robot pose, say \(\boldsymbol{q}_0\), the controlled robot arm (57) will eventually reach \(\boldsymbol{q}_{d}\). In other words, if we define the joint error as
we want to design a controller \( \boldsymbol{u}=\textbf{controller}(\boldsymbol{q}, \boldsymbol{\dot{q}}, \boldsymbol{q}_d, \boldsymbol{\dot{q}}_d)\) such that
PD Controller with Gravity Compensation
Controller for PD control with gravity compensation follows
with \(\boldsymbol{K}_{P}\) and \(\boldsymbol{K}_{D}\) are positive definite matrices.
Below, we will use the Lyapunov method (see background of Lyapunov method in Numerical Inverse Kinematics) to prove that the controller (54) works.
Lyapunov stability proof for PD controller (click to expand)
First, we define the error state vector \(\begin{bmatrix}\boldsymbol{e}\\ \boldsymbol{\dot{q}}\end{bmatrix}\), and choose the following Lyapunov function:
where \(\boldsymbol{K}_{P}\) is an \((n \times n)\) symmetric positive definite matrix.
Differentiating \(V({\boldsymbol{e}},\dot{\boldsymbol{q}})\) with respect to time yields
From (51), we can solve for \(\boldsymbol{B} \ddot{\boldsymbol{q}}\) and substituting it to (55) gives
The first term is zero since \(\dot{\boldsymbol{B}}-2 \boldsymbol{C}\) is a skew-symmetric matrix (see in the property of dynamics in Dynamics). For the second term, we substitute the controller (54) in, and this leads to
and thus, \(V\) decreases as long as \(\dot{\boldsymbol{q}} \neq \mathbf{0}\). Thus, the robot arm will reach an equilibrium configuration where \(\dot{\boldsymbol{q}}=\mathbf{0}\). To find the equilibrium configuration, we look at the closed-loop dynamics under control
With \(\dot{\boldsymbol{q}}=\mathbf{0}\), it follows that \(\ddot{\boldsymbol{q}} =\mathbf{0}\), and then from the above dynamics (57), we have
Therefore, the robot arm will eventually reach equilibrium, which is exactly the desired configuration \(\boldsymbol{q}_{d}\).
The control block diagram for PD control with gravity compensation is shown below
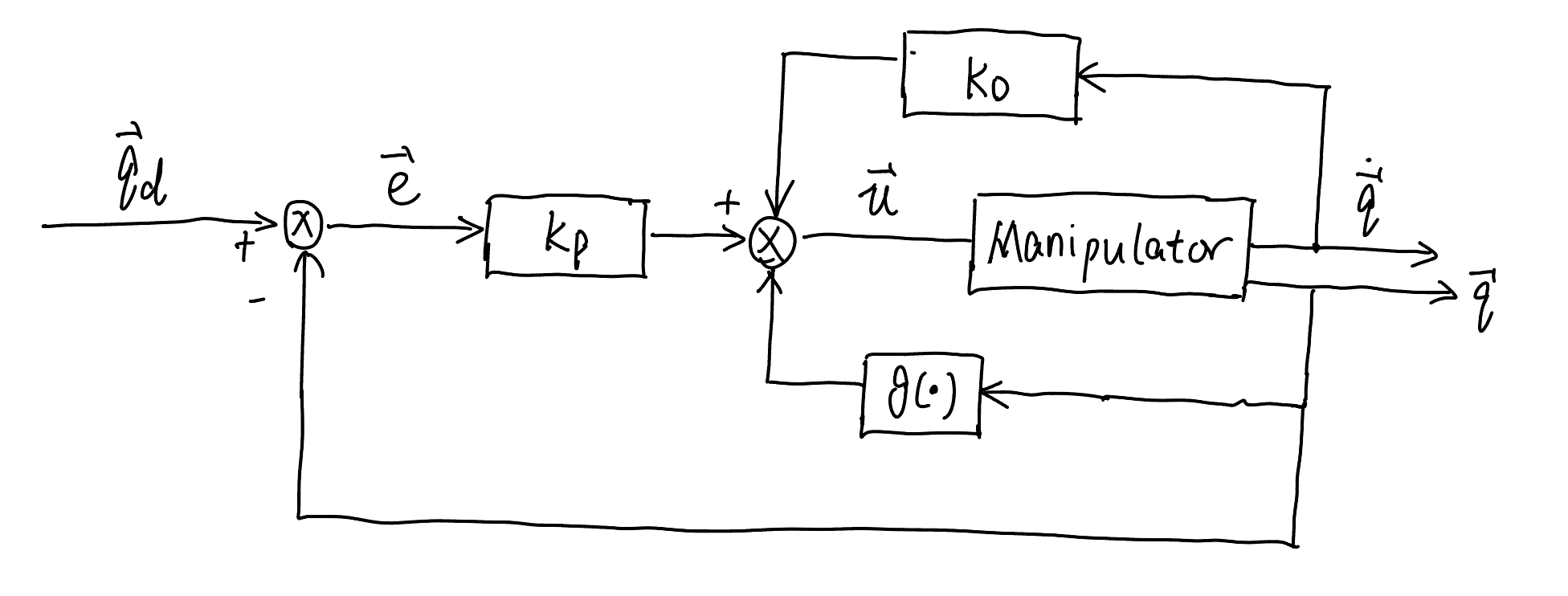
Fig. 67 Control diagram of PD control with gravity compensation#
Controller 2: Inverse Dynamics Control#
One limitation of the PD Control with Gravity Compensation is that the controller can only follow a stationary desired \(\boldsymbol{q}_d\), not good at tracking a fast-changing desired joint:
Inverse dynamics control is to address the above limitation. The idea of inverse dynamics control is to find a controller (52) that can make the robot arm behave like a mass-spring-damper system.
Inverse Dynamics Control
Controller for inverse dynamics control follows
with
Here,
with \(\zeta_i\) the damping ratio and \(\omega_{i}\) the natural frequency for joint \(i\).
Stability proof for Inverse Dynamics Control (click to expand)
Plugging the controller (59) into the robot arm dynamics (51), we have
which is simplified to
Considering (60), we have
Again, if we define the error \(\boldsymbol{e}={\boldsymbol{q}}_{d}-{\boldsymbol{q}}\), the above (63) becomes
which is the error dynamics. This is a standard second-order error (mass-spring-damper) system, where its convergence depends on the value of \(\boldsymbol{K}_P\) and \(\boldsymbol{K}_D\).
Then, the controlled robot arm can be viewed as having \(n\) decoupled (liner) second-order (mass-spring-damper) subsystems. Here, \(\zeta_i\) is the damping ratio and \(\omega_{i}\) the natural frequency for joint \(i\). For each joint \(i\), the error dynamics is
Please see my Minimal notes on control basics or below for how the values of the damping ratio \(\zeta_i\) and natural frequency \(\omega_{i}\) affect the error response \(\boldsymbol{e}(t)\) in time domain.
The control block diagram for inverse dynamics control is shown below
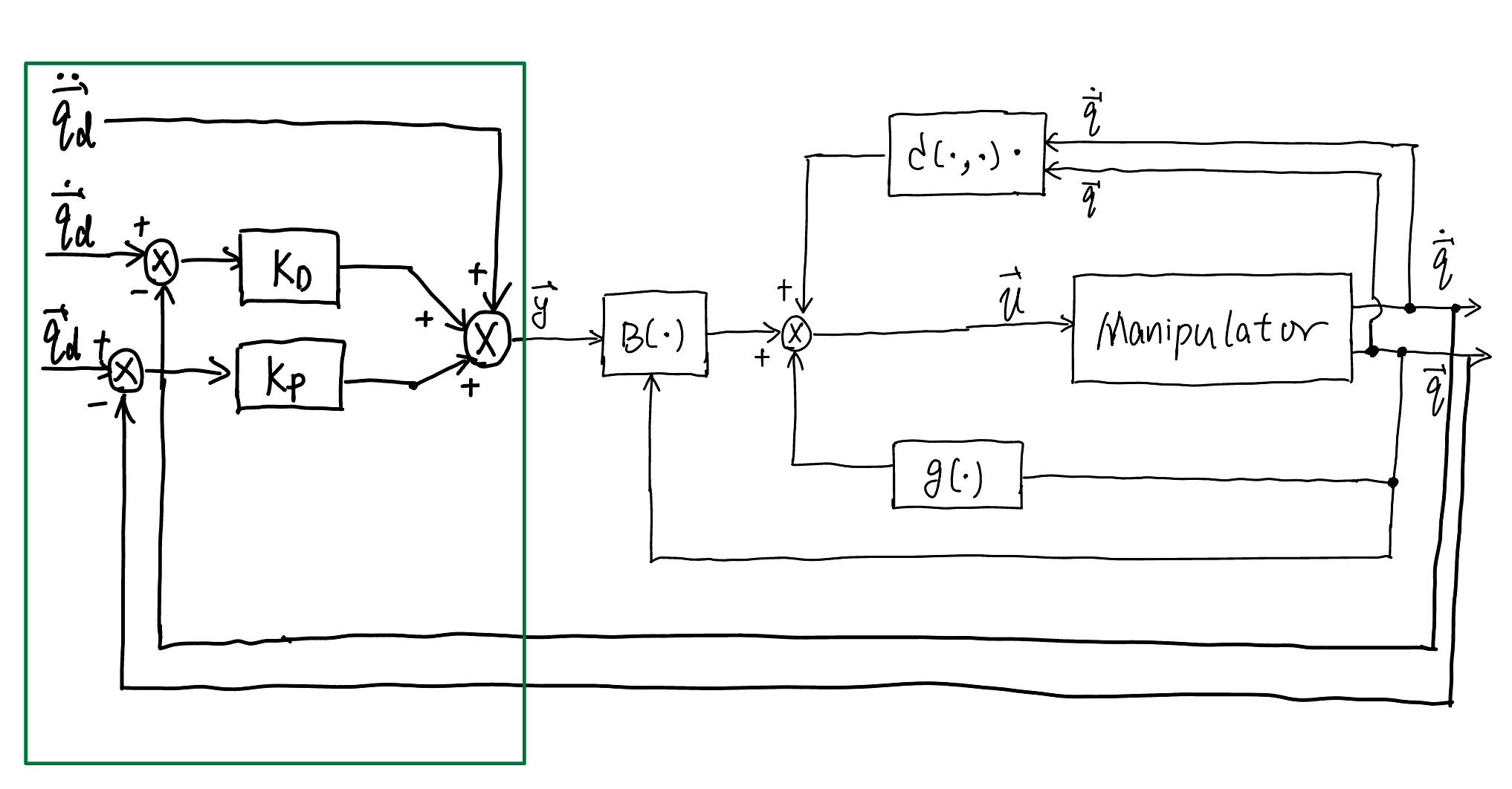
Fig. 68 Control diagram of joint space inverse dynamics control#
Controller 3: Impedance Control#
Impedance control specifies a desired dynamic relationship between the joint tracking error and the applied torque so that the robot behaves like a virtual mass-damper-spring system in joint space. In joint coordinates, a common impedance law is
where
\(\tilde{\boldsymbol{e}}=\boldsymbol{q}-\boldsymbol{q}_d\) is the tracking error (note sign convention),
\(\boldsymbol{M}_d,\boldsymbol{D}_d,\boldsymbol{K}_d\) are the (positive definite) desired inertia, damping and stiffness matrices in joint space,
\(\boldsymbol{\tau}_{cmd}\) is the commanded joint torque that enforces the impedance.
One practical controller that implements joint-space impedance while compensating robot dynamics is
Joint impedance control
The controller for joint impedance control follows:
with \(\boldsymbol{M}_d,\boldsymbol{D}_d,\boldsymbol{K}_d\) are (positive definite) desired inertia, damping and stiffness matrices in joint space.
This controller uses model compensation (the \(\boldsymbol{B},\boldsymbol{C},\boldsymbol{g}\) terms) so that the closed-loop joint dynamics approximate
Remarks and design notes:
Choosing \(\boldsymbol{M}_d\) small makes the system more responsive (low apparent inertia); larger \(\boldsymbol{K}_d\) increases stiffness around the desired pose.
Diagonal \(\boldsymbol{M}_d,\boldsymbol{D}_d,\boldsymbol{K}_d\) are common and simplify tuning: pick each joint’s stiffness and damping independently.
If the robot model is uncertain, reduce reliance on full model compensation and add robust terms (e.g., higher damping) or use adaptive/robust control techniques.
Simple discrete-time implementation (control loop at rate \(1/\Delta t\)):
# assume numpy imported as np, and functions get_q(), get_qdot(), send_torque(tau)
M_d = np.diag([0.5]*n) # desired inertia (example)
D_d = np.diag([5.0]*n) # desired damping
K_d = np.diag([50.0]*n) # desired stiffness
def impedance_step(q_d, q_d_dot, q, q_dot):
e = q - q_d
v = q_dot - q_d_dot
# feedforward term (can include desired accel if available)
tau = B(q) @ np.linalg.solve(M_d, (K_d @ (-e) - D_d @ v)) + C(q, q_dot) @ q_dot + g(q)
return tau
# in real loop:
# q, q_dot = read_sensors()
# tau_cmd = impedance_step(q_d, q_d_dot, q, q_dot)
# send_torque(tau_cmd)
Include this section as a basis for experiments in class: students can vary \(\boldsymbol{K}_d\) and \(\boldsymbol{D}_d\) to observe compliant vs stiff behavior in simulation or on hardware.