Welcome to the Intelligent Robotics and Interactive Systems (IRIS) Lab at ASU. We study contact-rich physical intelligence: how robots learn to act through physical interaction with objects, environments, and humans. Our goal is to develop robots that can understand and exploit contact to achieve dexterity, robustness, and adaptability in the real world.
-
Physics-grounded contact-rich dexterity. We develop methods that fuse robot learning with contact physics, enabling robots to use contact as a central tool for dexterous manipulation beyond pick-and-place, e.g., dynamic reorientation, sliding, rolling, etc.
-
Control-theoretic learning from humans. We develop methods that allow robots to learn from sparse human demonstrations, corrections, and feedback, while providing principled confidence in learning efficiency, reliability, and safety.
Below are selected demos from our lab. For more details, please see the Good Papers page.
ComFree: Scalable Contact Physics Engine
ComFree-Sim is our complementarity-free contact physics engine for contact-rich simulation. It computes contact dynamics analytically and scales efficiently with contact count, achieving over 5× higher throughput than MuJoCo Warp in dense-contact benchmarks.
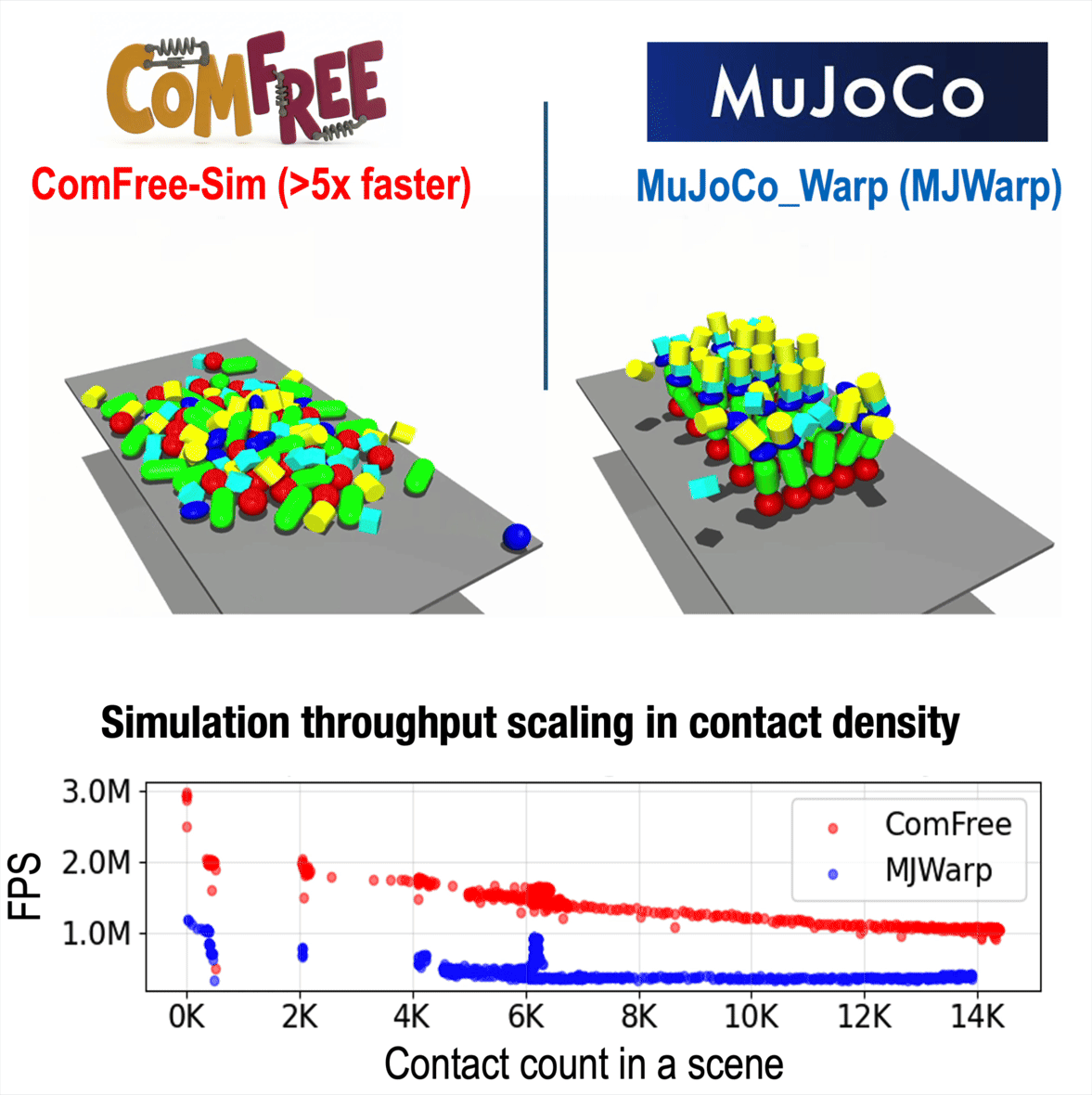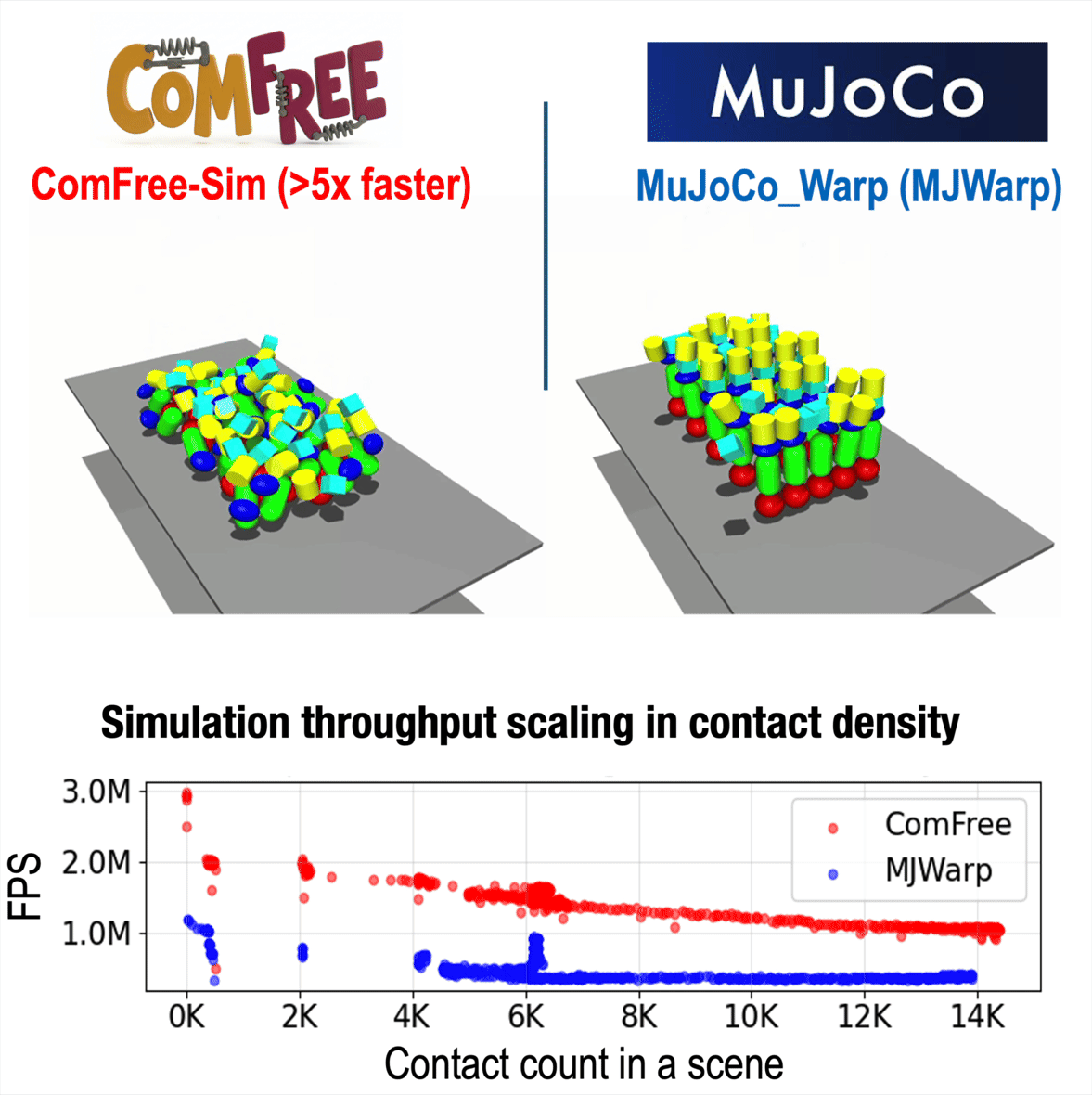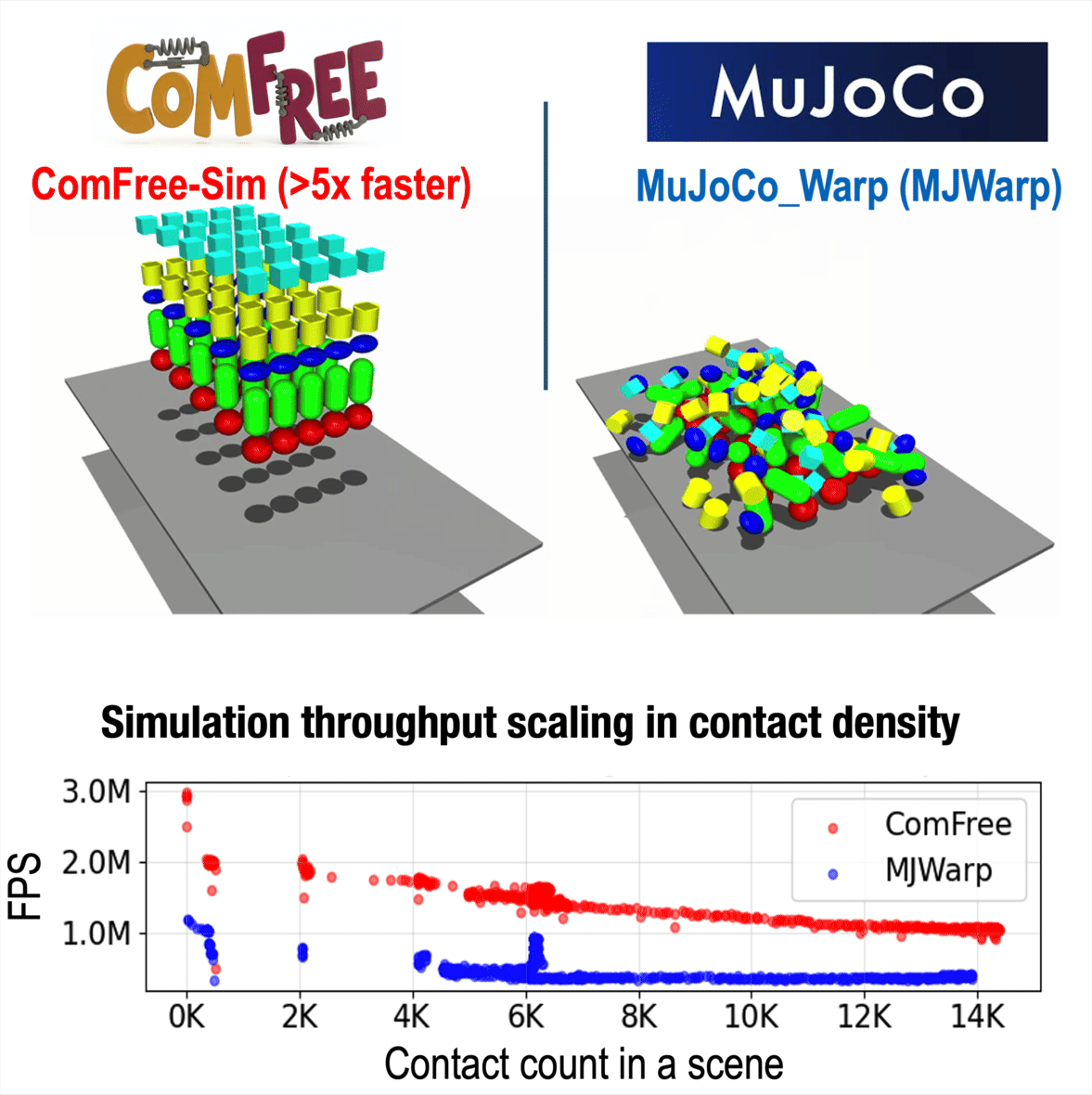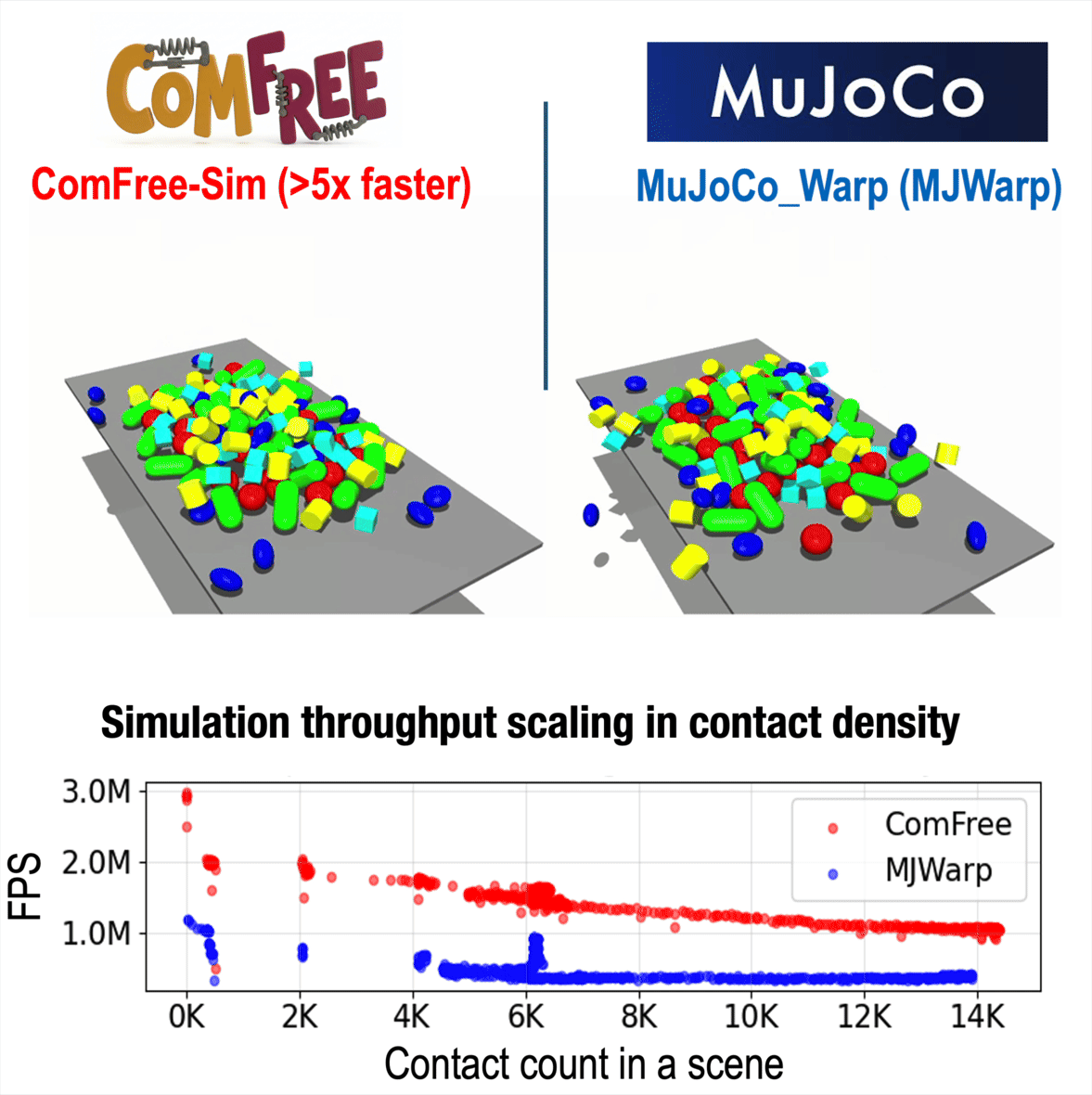
Online (~100Hz) Optimization Through Contact
Our ComFree predictive control policy online plans contact-rich actions at 100 Hz, automatically deciding where, when, and how to make contact for diverse manipulation and locomotion tasks.



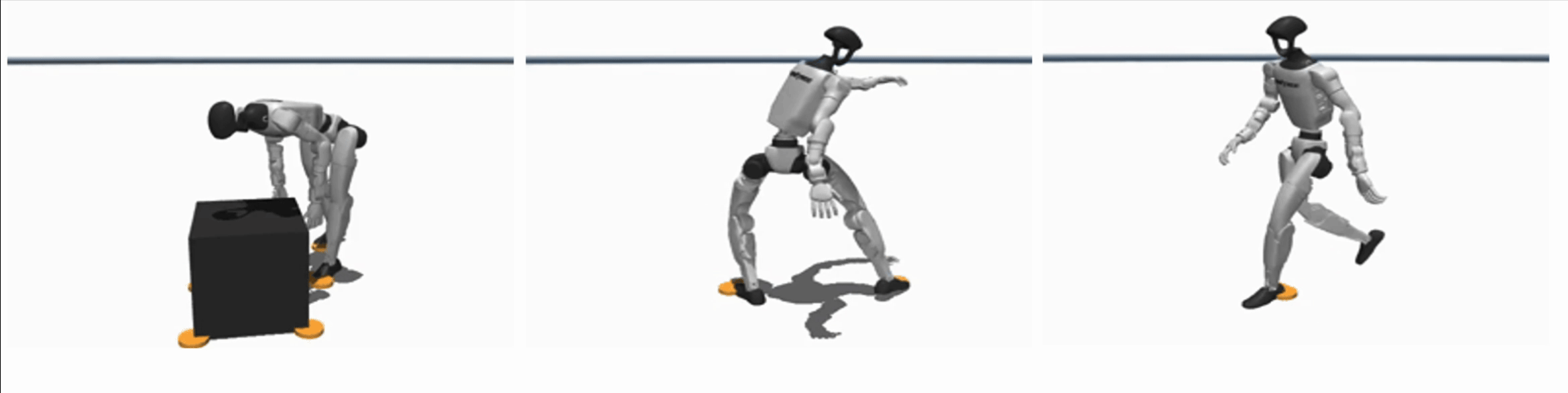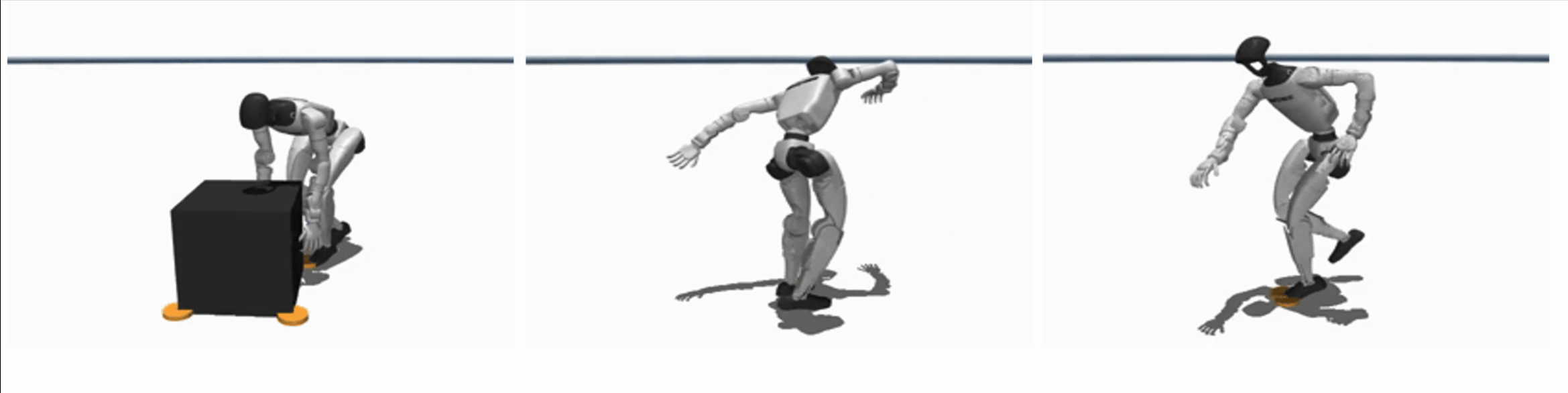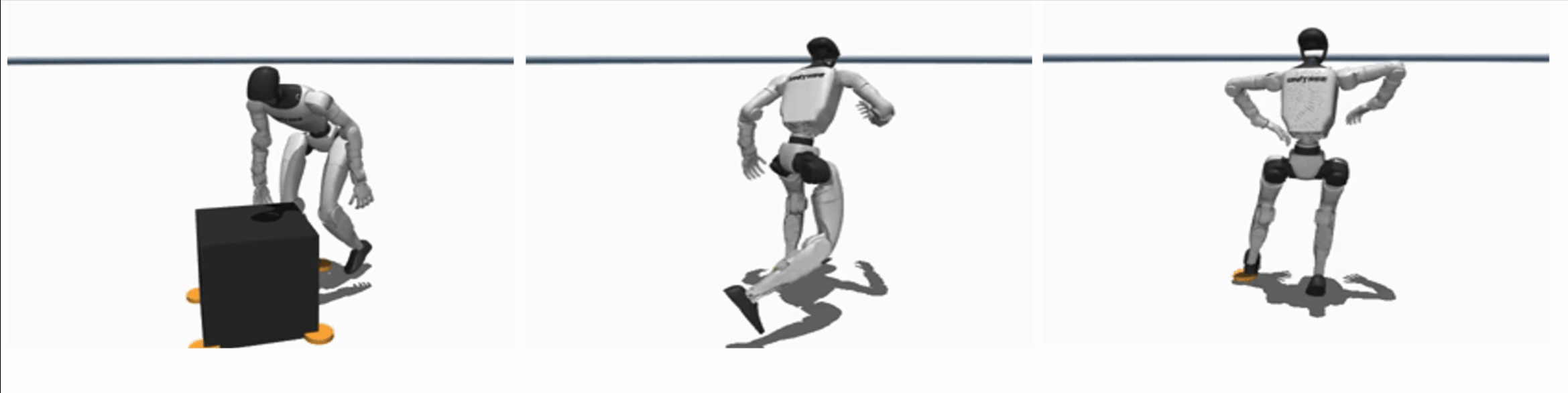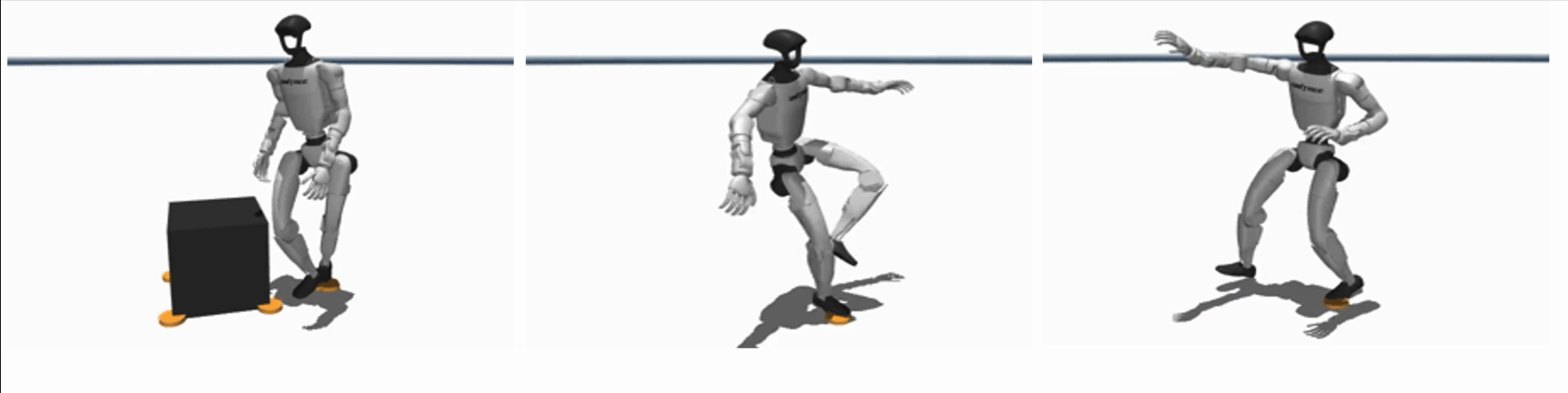


Efficient Learning of Contact-Rich Dexterity
By embedding contact-physics structure into learning, our methods reduce data needs by over 10× for contact-rich manipulation, enabling zero-shot sim2real transfer or learning directly on hardware within few minutes.


Pixel to Contact Physics (Real-to-Sim)
Our methods turn videos into simulation-ready physical engines (real2sim) for contact-rich manipulation, by jointly estimating contact geometry, pose, and physics properties from pixels.

Recent Updates
🎉 Wanxin Jin has been appointed as an Associate Editor for IEEE Transactions on Robotics (T-RO).
📢 Wanxin Jin gave a talk at The University of Texas at Dallas (UT Dallas), hosted by the Intelligent Robotics and Vision Lab, titled "Physics as the Backbone of Dexterity: Scalable Contact Simulation, Optimization, and Physics-Grounded Learning."
See the 𝕏 post for more details.🚀 We released ComFree-Sim, a GPU-parallelized analytical contact physics engine for scalable contact-rich robotics simulation and control.
Check out the 𝕏 post, paper, documentation, and video demo.📢 Wanxin Jin gave a Robotics Seminar at University of Illinois Urbana-Champaign (UIUC), titled "Physics as the Backbone of Dexterity: Scalable Contact Simulation, Contact-Aware Control, and Physics-Grounded Learning."
See the event page and video recording.㊗️ 🎉: Congratulations to Zhixian Xie! His paper "Safe MPC Alignment with Human Directional Feedback" has been accepted to IEEE Transactions on Robotics (T-RO).
See our previous 𝕏-Twitter and YouTube for more details.🎓👏 Huge congratulations to our IRIS Lab master’s graduates! Aravind Prakash Senthil has accepted a Software Engineer offer at American Express, and Swetha Tirumala is joining Matic Robots. We’re incredibly proud of their accomplishments and can’t wait to see their impact.
📢 Wanxin Jin will give an invited talk at General Motors' (GM) Research and Development, titled "Leveraging Ultra-fast Physics Engines for Real-Time and Dexterous Manipulation"