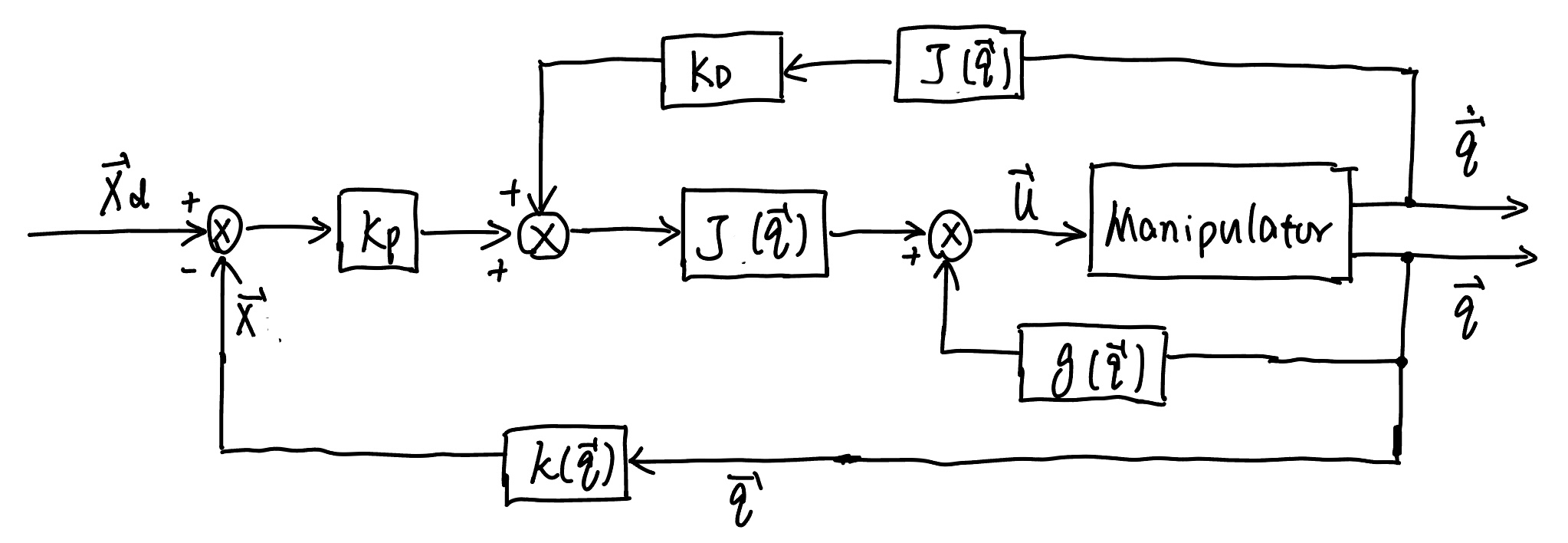
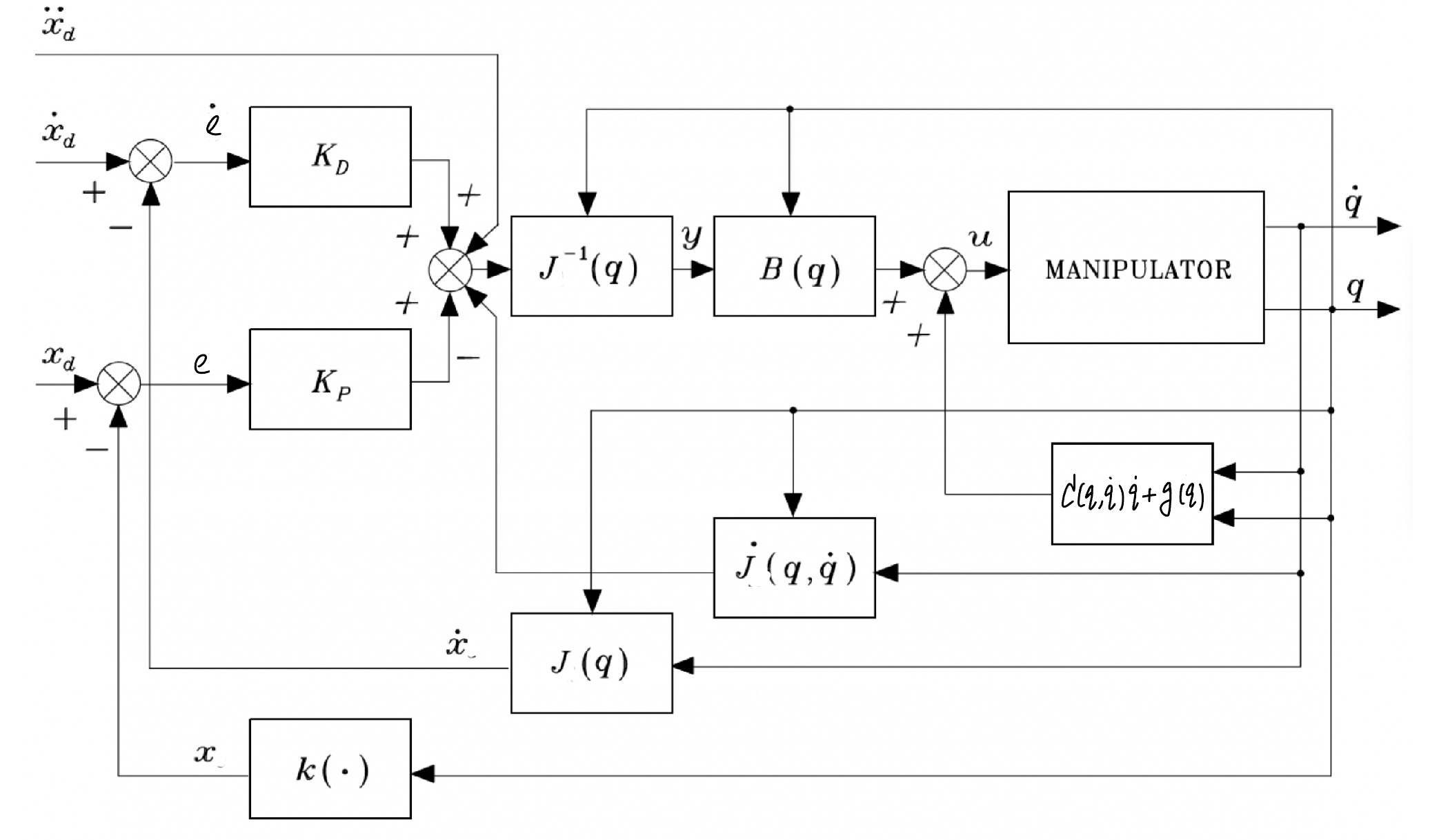
The goal of operational space control (OSC) is to control the robot to track the desired end-effector pose \(\boldsymbol{x}_d\) and velocity \(\boldsymbol{\dot{x}}_d\) given in the operational space.
In the following control design, we consider a a \(n\)-joint robot arm without external end-effector forces and any joint
friction. The equation of motion of the robot arm is
i.e., the controller takes as input the robot arm’s current joint
position \(\boldsymbol{q}\), current joint velocity
\(\boldsymbol{\dot{q}}\), the desired end-effector pose
\(\boldsymbol{x}_d\), and desired end-effector velocity
\(\boldsymbol{\dot{x}}_d\), and outputs the joint torque \(\boldsymbol{u}\).
Thus, the controlled robot arm with the controller has the equation of motion:
Given a stationary end-effector pose \(\boldsymbol{x}_{d}\) (i.e., \(\boldsymbol{\dot x}_{ d}=\boldsymbol{0}\)), we want to design a controller (88)
such that from any initial robot configuration \(\boldsymbol{q}_0\), the controlled robot arm (89) will eventually reach
\(\boldsymbol{x}_{d}\). That means
Below, we will design the controller (88) based on the Lyapunov method (see
background of Lyapunov method in Numerical Inverse Kinematics).
First, we take the
vector \(\begin{bmatrix}\boldsymbol{e}\\
\boldsymbol{\dot{q}}\end{bmatrix}\) as the control system state. Choose
the following positive definite quadratic form as Lyapunov function:
Similar to the derivation in the previous chapter, we replace
\(\boldsymbol{B}\ddot{\boldsymbol{q}}\) in (93) form dynamics (87)
and consider the property that
\(\dot{\boldsymbol{B}}-2 \boldsymbol{C}\) is a
skew-symmetric matrix.
Then, (93) becomes
which says the Lyapunov function decreases as long as
\(\boldsymbol{J}(\boldsymbol{q})\dot{\boldsymbol{q}} \neq \mathbf{0}\).
Thus, the system reaches an equilibrium pose, with condition
\(\dot{V}= 0\) and
\(\boldsymbol{J}(\boldsymbol{q})\dot{\boldsymbol{q}}=\mathbf{0}\).
We
consider the non-redundant non-singularity of matrix
\(\boldsymbol{J}(\boldsymbol{q})\). Then, the equilibrium condition
\(\boldsymbol{J}(\boldsymbol{q})\dot{\boldsymbol{q}}=\mathbf{0}\) means
that \(\dot{\boldsymbol{q}}=\mathbf{0}\) and further
\(\ddot{\boldsymbol{q}} =\mathbf{0}\). To find the robot equilibrium configuration, we look at the robot arm dynamics with controller
One limitation of the OSC PD Control is that the controller can only follow a stationary desired \(\boldsymbol{x}_d\)
, but is not good at tracking a fast-changing desired \(\boldsymbol{x}_d\) (i.e., \(\boldsymbol{\dot x}_d\neq \boldsymbol{0}\)). OSC Inverse Dynamics Control is to address so.
Recall the joint space inverse dynamics control in the previous chapter. If we set the controller as
form
Again, we will discuss how to set
this new input \(\boldsymbol{y}\) below. The new input \(\boldsymbol{y}\) is designed make the robot arm track a changing \(\boldsymbol{x}_{d}(t)\). To this end, we
differentiate the jacobian equation
which describes the operational space error dynamics, with
\(\boldsymbol{K}_{P}\) and \(\boldsymbol{K}_{D}\) determining the error
convergence rate to zero. Typicaly we choose
with with \(\zeta_i\) the damping ratio and \(\omega_{i}\) the natural frequency.
Then, the end-effector of the controlled robot arm will behave like a linear second-order (mass-spring-damper) system.
The resulting OCS inverse dynamics control diagram is shown below.
Fig. 80 Block scheme of operational space PD control with gravity
compensation#
In sum, we recapitulate the operational space inverse dynamics control below